Evaluating AI Properly


AI systems can be powerful tools for your business or community group. However before you invest, the most important question to ask is “will this actually work for us?”. It turns out that’s a surprisingly difficult question to answer. The AI marketplace is growing rapidly, with new vendors appearing constantly, and not all of them evaluate their own products rigorously. Understanding a few key concepts can help you cut through the noise, ask the right questions, and avoid some costly mistakes.
A simple method to evaluate might be this: the AI makes 100 decisions, we evaluate how many it gets right, and present that percentage. This is also known as accuracy. While it is easy to understand, as we’ll see, this is a poor way to measure the effectiveness of an AI model.
Keep these three golden rules to keep in mind when evaluating AI - ask your vendors about how their evaluation stacks up against these concepts:
Let’s dive into these golden rules in more detail, and see some common real world issues. Tools exist to support this type of analysis, but we’ll stick to general concepts rather than specific tools.
Imagine you are evaluating an AI system that identifies if fruit is ripe for picking. During training, fruit is photographed in a lab, with a high quality camera, great lighting, and from a limited range of viewports. The model performs very well during training! However once it gets to the real world, this supposed quality drops significantly.
Lab-based evaluations of models often overestimate AI quality. The real world is messy, complicated, and continuously changing. Your evaluation procedure needs to reflect this.
One of the best ways to evaluate an AI system is to create your own dataset in real world conditions. Take your own photos, in your real farm, for testing purposes. Use a similar camera to what the AI system would use (or a variety of cameras if you do not know). Take photos at different times of the day, in different weather and seasons, and throughout the full growing cycle. Label the data yourself – is the fruit ready or not? Then, use your dataset to evaluate the AI system.
Additionally, you need to continuously update your testing. The real world changes. Each year we go through different seasons. Culture changes – imaging a system for counting people in a store that is unable to count properly with a new fashion trend of bright jackets. A test that was performed a few years ago may not be relevant anymore – this is known as model degradation and it affects nearly all AI systems eventually. In the farm, the variety of fruit you grow might change with changing preferences. This is known as model degradation, and we’ll revisit this point in particular in a future article.
Accuracy, by itself, is not a good evaluation metric. For instance, take a fraud detection system for a bank. Most transactions a bank handles are not fraudulent, so all a system needs to do to get a 95% accuracy (or even higher!) is to label everything as “not fraud”. Instant success!
The cause of this issue is that this is an “imbalanced” dataset where one outcome (is-fraud) is significantly more likely than other scenarios (no-fraud). Many real-world outcomes are like this. For example, most medical tests are “negative” for whatever disease they are looking for (most people do not have most diseases). Most images you take of growing fruit on a farm are “not yet ripe”. Most customers in a store are not shoplifting.
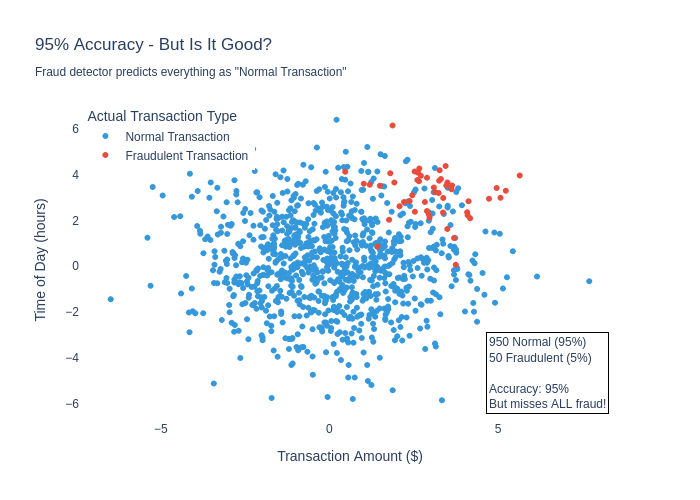
How do we fix this? There are quite a few evaluation metrics that are better, but a simple method is to break down the predictions into four categories. Using fraud-detection as an example:
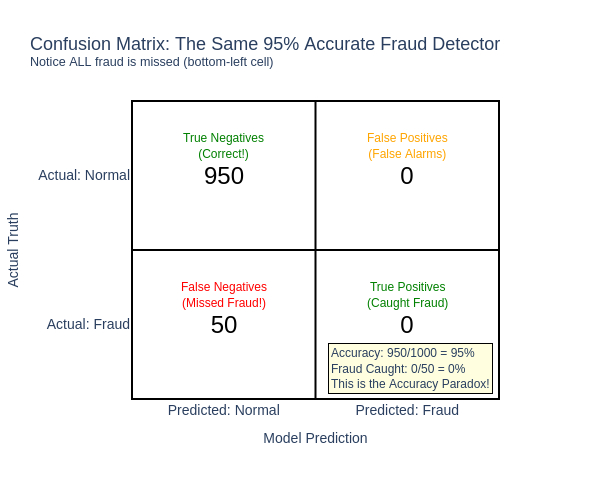
Now the failure is more clear – the model does not perform well on the most important part of the system - identifying fraud. It gets lots of True Negative cases, but zero True Positives! The model is 95% accurate but detects 0% of fraud. This is the second “Golden Rule” in action – measure what matters.
Unfortunately there is no “single number” that makes sense for all applications. Determine yourself the cost or benefit on each of these outcomes. For example, missing a case of fraud might cost the company $500 on average. Investigating a false alarm might cost $200 on average. Identifying fraud early saves us $400. With these values we can now work out the overall benefit of the fraud system.
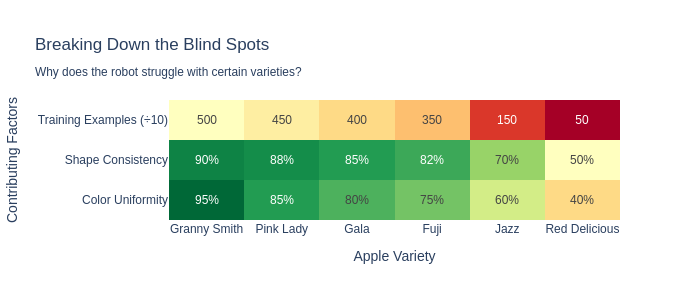
Diving deeper into the statistics can identify blind spots in your model. The AI model might perform well in some scenarios, but not as well in others. Fixing these can involve re-training the model with new data, adding a new specialist model (“if the fruit looks like an apple, use a different system”), or perhaps an entirely new technique is needed. In our fruit picking example, this could be as simple as identifying the success rate of the system per variety, shown in the following plot.
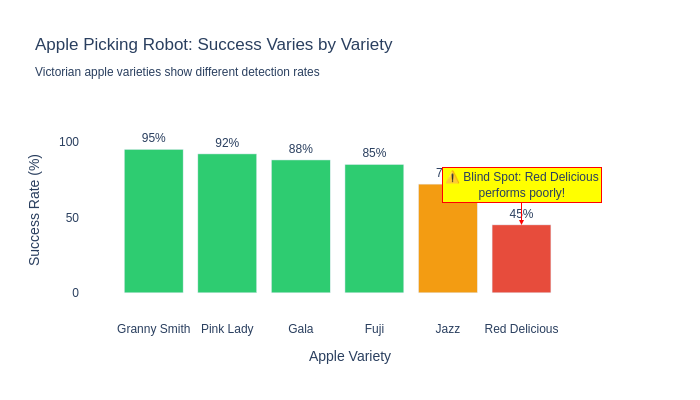
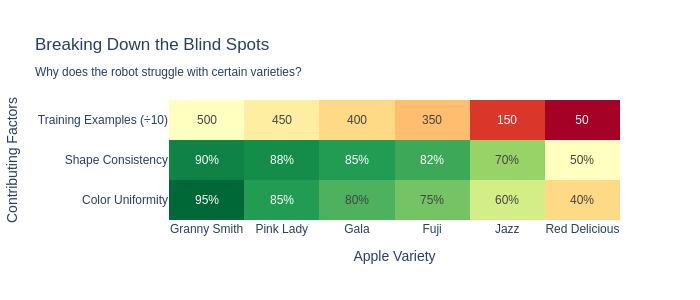
As we dive deeper, we might want to identify “why”. We can then analyse the results in much more detail, which might help us fix the issue in future models, or create systems that compensate for the identified issues. The following table shows that as we break down why, we can see more clear patterns.
Another blind spot is around accessibility and discrimination. For example, early “face unlocking” systems in phones were quite effective – as long as you were a white adult male. They often struggled with darker skin tones and non-Caucasian features. The cause was often quite simple – many of the people in the team that developed the system were white, and it worked for them. Once it hit the real world, a more diverse audience quickly found the problem. Ensure you are testing for your whole audience, not just the people immediately around you. (Sidenote: it is worth noting that today most facial recognition is much better in this regard, but issues still persist.)
All of these evaluations can be done by you, outside the AI system, to evaluate how the model will work for you. Ensure that you are adequately evaluating AI systems you bring into your business, and don’t be afraid to dive a little deeper into the numbers. Proper evaluation is the difference between a valuable tool and an expensive mistake.
What works for the market in general might not work for your specific use-case, and it might not be clear if, or why, this is the case until we investigate. Your specific scenarios might be different, requiring re-training models, updating data workflows, or other interventions to improve results.
At BRAIN we want people to use AI effectively. We can assist with creating evaluation processes, running evaluations on products, and providing independent advice. If you are unsure how to evaluate an AI product for your business, we can help.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.